Again, spanish only because it's a video... in spanish.
Resulta que me olvidé que sí habían grabado mi charla de docutils y compañia. Gracias a Germán por hacerme acordar y mostrarme adonde estaba!
rst2pdf es una herramienta para convertir restructured text a PDF usando reportlab en vez de LaTeX.
Se ha usado para muchas cosas desde libros a revistas, a folletos, a manuales, a sitios web y tiene muchos features:
Font embedding (TTF or Type1 fonts)
Cascading Stylesheets
Arquitectura de plugins muy flexible (permite hacer cosas como crear los encabezados en base a SVG arbitrarios!)
Integración con Sphinx.
Múltiples layouts de página
Tapas customizables via templates
Y mucho, mucho más
El cambio más grande en 0.16 es probablemente el soporte de Sphinx 1.0.x, si estás usando Sphinx esta es la versión que querés.
Aparte de eso, una tonelada de bugs arreglados, y algunos features menores.
Este es el changelog completo:
Fixed Issue 343: Plugged memory leak in the RSON parser.
Fix for Issue 287: there is still a corner case if you have two sections
with the same title, at the same level, in the same page, in different files
where the links will break.
Fixed Issue 367: german-localized dates are MM. DD. YYYY so when used in sphinx's
template cover they appeared weird, like a list item. Fixed with a minor workaround in
the template.
Fixed Issue 366: links to "#" make no sense on a PDF file
Made definitions from definition lists more stylable.
Moved definition lists to SplitTables, so you can have very long
definitions.
Fixed Issue 318: Implemented Domain specific indexes for Sphinx 1.0.x
Fixed Index links when using Sphinx/pdfbuilder.
Fixed Issue 360: Set literal.wordWrap to None by default so it doesn't inherit
wordWrap CJK when you use the otherwise correct japanese settings. In any case,
literal blocks are not supposed to wrap at all.
Switched pdfbuilder to use SplitTables by default (it made no sense not to do it)
Fixed Issue 365: some TTF fonts don't validate but they work anyway.
Set a valid default baseurl for Sphinx (makes it much faster!)
New feature: --use-numbered-links to show section numbers in links to sections, like "See section 2.3 Termination"
Added stylesheets for landscape paper sizes (i.e: a4-landscape.style)
Fixed Issue 364: Some options not respected when passed in per-doc options
in sphinx.
Fixed Issue 361: multiple linebreaks in line blocks were collapsed.
Fixed Issue 363: strange characters in some cases in math directive.
Fixed Issue 362: Smarter auto-enclosing of equations in $...$
Fixed Issue 358: --real--footnotes defaults to False, but help text indicates default is True
Fixed Issue 359: Wrong --fit-background-mode help string
Fixed Issue 356: missing cells if a cell spawns rows and columns.
Fixed Issue 349: Work correctly with languages that are available in form aa_bb and not aa (example: zh_cn)
Fixed Issue 345: give file/line info when there is an error in a raw PDF directive.
Fixed Issue 336: JPEG images should work even without PIL (but give a warning because
sizes will probably be wrong)
Fixed Issue 351: footnote/citation references were generated incorrectly, which
caused problems if there was a citation with the same text as a heading.
Fixed Issue 353: better handling of graphviz, so that it works without vectorpdf
but gives a warning about it.
Fixed Issue 354: make todo_node from sphinx customizable.
Fixed bug where nested lists broke page layout if the page was small.
Smarter --inline-links option
New extension: fancytitles, see //ralsina.me/weblog/posts/BB906.html
New feature: tab-width option in code-block directive (defaults to 8).
Fixed Issue 340: endnotes/footnotes were not styled.
Fixed Issue 339: class names using _ were not usable.
Fixed Issue 335: ugly crash when using images in some
specific places (looks like a reportlab bug)
Fixed Issue 329: make the figure alignment/class attributes
work more like LaTeX than HTML.
Fixed Issue 328: list item styles were being ignored.
Fixed Issue 186: new --use-floating-images makes images with
:align: set work like in HTML, with the next flowable flowing
beside it.
Fixed Issue 307: header/footer from stylesheet now supports inline
rest markup and substitutions defined in the main document.
New pdf_toc_depth option for Sphinx/pdfbuilder
New pdf_use_toc option for Sphinx/pdfbuilder
Fixed Issue 308: compatibility with reportlab from SVN
Fixed Issue 323: errors in the config.sample made it work weird.
Fixed Issue 322: Image substitutions didn't work in document title.
Implemented Issue 321: underline and strikethrough available
in stylesheet.
Fixed Issue 317: Ugly error message when file does not exist
Una manera (si estás programando en Python) es usar Yapsy..
Yapsy es asombroso. También, carece completamente de documentación
entendible. Veamos si este post arregla un poco esa parte y deja
sólo lo asombroso.
Update: No había visto la documentación nueva de Yapsy. Es mucho mejor que la que había antes :-)
Esta es la idea general con yapsy:
Creás un Plugin Manager que puede encontrar y cargar plugins de una
lista de lugares (por ejemplo, de ["/usr/share/appname/plugins",
"~/.appname/plugins"]).
Una categoría de plugins es una clase.
Hay un mapeo entre nombres de categoría y clases de categoría.
Un plugin es un módulo y un archivo de metadata. El módulo define
una clase que hereda de una clase de categoría, y pertenece a
esa categoría.
El archivo de metadata tiene cosas como el nombre del plugin,
la descripción, la URL, versión, etc.
Una de las mejores cosas de Yapsy es que no especifica demasiado.
Un plugin va a ser simplemente un objeto Python, podés poner lo que
quieras ahí, o lo podés limitar definiendo la intefaz en la clase
de categoría.
De hecho, lo que vengo haciendo con las clases de categoría es:
Arranco con una clase vacía
Implemento dos plugins de esa categoría
Los pedazos en común los muevo dentro de la categoría.
Pero créanme, esto va a ser mucho más claro con un ejemplo :-)
Lo voy a hacer con una aplicación gráfica en PyQt, pero Yapsy funciona
igual de bien para aplicaciones "headless" o para líneas de comando.
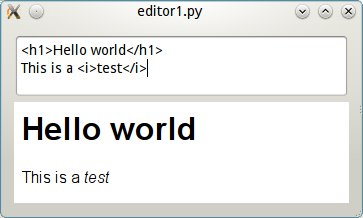
Comencemos con algo simple: un editor HTML con un widget preview.
Un editor simple con preview
Este es el código de la aplicación, que es realmente simple (no puede guardar
archivos ni nada interesante, es sólo un ejemplo):
Pero esta aplicación tiene un obvio límite: hay que escribir HTML! Por qué no
escribir python y que lo muestre resaltado en HTML? O markup de Wiki! O reStructured
text!
Uno podría, en principio, implementar todos esos modos, pero estás asumiendo
la responsabilidad de soportar cada cosa-que-se-convierte-en-HTML. Tu aplicación
sería un monolito. Ahí entra Yapsy.
Creemos entonces una categoría de plugins, llamada "Formatter" que toma texto plano
y devuelve HTML. Después agreguemos cosas en la UI para que el usuario pueda elegir
que formatter usar, e implementemos un par.
Esta es la clase de categoría de plugins:
Por supuesto que no sirve de nada sin plugins! Asi que creemos un par.
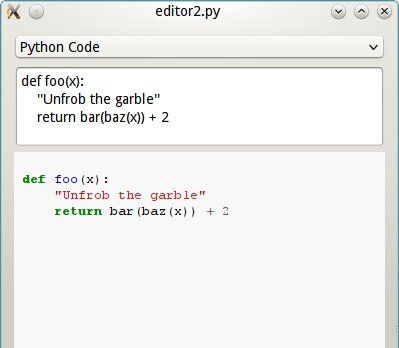
Primero, un plugin qye toma código python y devuelve HTML, usando pygments.
Como ven, eso va en una carpeta plugins. Después le decimos a Yapsy que
busque los plugins ahi adentro.
Para ser reconocido como un plugin, necesita metadata:
Y realmente, eso es todo lo que hay que hacer para hacer un plugin. Acá
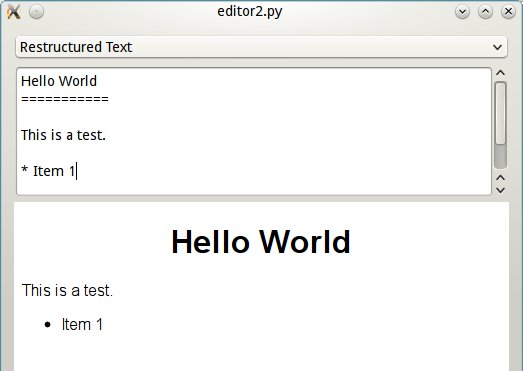
hay otro para comparar, que usa docutils para formatear reStructured Text:
Y acá están en acción:
reSt mode
Python mode
Of course using categories you can do things like a "Tools" category, where the
plugins get added to a Tools menu, too.
Este es el código del lado de la aplicación:
Resumiendo: es fácil, y te lleva a mejorar la estructura interna de tu aplicación
y terminás con mejor código.
Por ejemplo, Aranduka está cerca de poder sincronizar mi colección de libros con my teléfono. Pero... que pasa si lo que quiero leer en el tren no es un libro sino un blog?
Bueno, los blogs te dan feeds. Y un feed es una colección de pedazos de HTML pegoteados en una estructura más unos datos como autor y cosas así.
Y hay un módulo excelente para parsearlos, qu se llama feedparser. Y yo no escribí uno, ni dos, ni tres, sino cuatro programas para leer RSS!
Entonces, porqué no convertir el feed en algo que mi teléfono pueda digerir? [#] Es difícil?
Bueno... no mucho. Fue cuestión de tomar un documento ePub chiquito de ejemplo (generado con Calibre), escribir algunos templates, darle los datos de feedparser, y zipear todo.
Por ejemplo, este archivo es este blog como ePub y así se ve FBReader leyéndolo.
No es código interesante, y requiere templite feedparser y quién sabe que mas.
El ePub producido no valida, y probablemente nunca lo haga, ya que tiene pedazos de los feeds originales adentro, por lo que la validación no depende de rss2epub.
Además no tenés imágenes. Eso implicaría parsear y arreglar todos los elementos img o algo así y no tengo ganas en este momento.
[#] Este feature lo ví por primera vez en plucker hace añares, y sé que Calibre lo tiene.
Y... este no lo estoy haciendo solo, lo que lo hace más divertido.
Es un administrador de eBooks (o de libros en general?) que te ayuda a tener tus PDF/Mobi/FB2/loquesea organizados, y debería
eventualmente sincronizarlos con el dispositivo que querés usar para leerlos.
Podés bajar libros de FeedBooks. Esos libros se descargan, se agregan a la base de datos, se etiquetan, se baja la tapa, etc. etc.
Podés importar tu carpeta actual de libros en bulto
Aranduka usa google y otros servicios para tratar de
adivinar (por los nombres) qué libro es ese y llenar
los datos extra.
Podés "adivinar" esos datos extra
Marcando como confiables algunos datos (por ejemplo,
el título) Aranduka busca candidatos que coincidan y
elegís el correcto.
Por supuesto que también se puede editar los datos
manualmente.
Y eso es todo por ahora. Features planeados:
Muchos como para hacer una lista.
La meta es clara:
Debe ser hermoso (y no lo es)
Debe ser potente (y todavía no)
Debe ser mejor que la "competencia"
Si no se logran esas tres metas, es un fracaso. Tal vez sea un fracaso divertido, pero igual es fracasar.