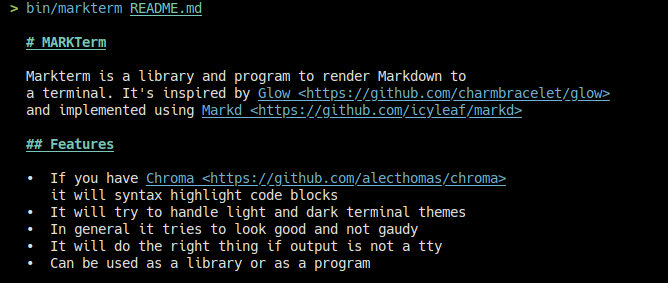
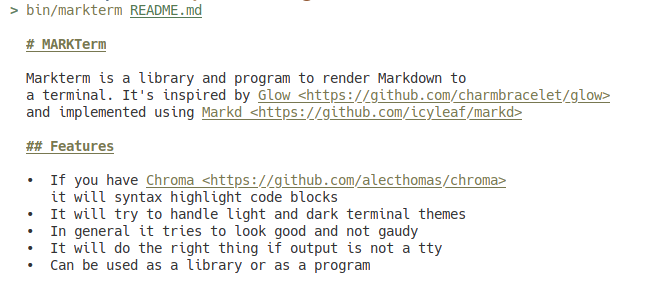
You can use it as a library from Crystal, or you can use the markterm binary.
It can syntax highlight code (as long as you have chroma installed), it does the right thing when piped to another program, and it tries to look good but not gaudy.
What will I use it for?
Showing CLI program's help. I am using docopt lately and the
format of the docopt input is almost markdown. With a bit
of flair it can be both, and using markterm I can show it
in a terminal in a much nicer way than usual.
Extra: why am I starting so many projects lately?
Because it makes me happy
Because in most cases it's not code that will need maintenance.
I expect markterm to just work for the next 10 years without
me touching it, if needed.
In a weekend. It helps that the thing is small (under 200LOC) but it's still
an indication that I am having fun doing it.
So, what is it? I wrote Crycco, a Crystal tool similar to Docco, which is a
literate programming tool.
A what?
A literate programming tool. Meaning a tool that lets you:
Generate a program's code out of a document
Generate a document out of a program's code
Generate a document and a program's code out of a "literate document"
That may be doing the opposite of explaining what it actually does, so
here's an example.
I wrote Crycco which if you look at it
looks like a normal, although very heavily commented crystal program.
But if you pass the source code for Crycco through crycco it produces the crycco website ... go take a look!
As you can see it's a detailed explanation of what the program does and
how the code works. It's the same thing only presented differently.
It's much easier to follow the explanations when they run alongside the code
rather than interrupting it, isn't it?
Let's see another example. Crycco uses a YAML file for some aspects of
its configuration. Usually I would just add some comments and tell you to
go and read the file.
What do you think is easier to read and more understandable?
So, there it is, and it's pretty usable, even if I still want to extend it
in some ways (like... let's generate Markdown! And use that to generate a PDF!
Like it's 1989 and we are using nuweb!)
Yes, literate programming has been dead for a couple of decades, but it's
far from a worthless idea. It can be used, it can be used purposefully
and be valuable, and I have ideas that can be achieved using Crycco or
a similar tool.
I am working a bit (slowly) on Nicolino a static site generator written in Crystal. One of the things it does is, it renders markdown files.
Since the markdown usage is limited to, like, 3 lines, I thought
"Why not try all the markdown libraries and see which one is faster?"
So, I did.
The benchmark is simple:
An empty Nicolino site.
4000 simple markdown files (a few lorem ipsum paragraphs)
Nicolino compiled in release mode
Render the whole site 10 times, average the last 7 runs
Here is a chart showing the times in seconds for each library without the time that is used in other things (NOOP's time, which was 2.62 seconds).
So, luce is much, much, much slower, and crystal-cmark is the fastest. And cr-discount (MY OWN BINDING) is much slower than
the others, which is a bit disappointing.
On the other hand, there are two sides to optimizing. One is choosing the fastest library, the other is not caring if the
difference is small in absolute, even if it's large in relative.
What does that mean?
This is over 4000 documents.
So, while cr-discount is slower, it's still rendering 4000 documents in 0.66 seconds. That's 0.000165 seconds per document.
That's 1.65 tenths of a thousand of a second. That's over 6000
documents per second.
If the normal usecase was to render thousands of documents,
then that would make a difference. But it's not. It's usually 3 documents.
So, as long as cr-discount has any feature I need and it's not
in the other libraries, it's fine to use it, and the same
goes for the others (except luce, I guess, but still: 757 documents per second is not bad).
Update: Compiling discount with -O3 brings it down to 0.48, which is bettern than 0.66
but makes no difference for the conclusions.
I host a number of static websites on my personal server. Over
the years, they have been served by a variety of web servers,
but I recently decided I wanted to make it easy.
So, I looked for a modern and minimalistic web server that
supported a feature of the venerable thttpd
That feature is automatic virtual hosts. The main idea is that
you have a folder and in there a bunch of subfolders, each one
is a site. And the name of the folder is the name of the site.
So, if I have /srv/ralsina.me then when a user asks for http://ralsina.me they get that. And if I have /srv/whatever.com and
the user asks for whatever.com they get that.
Also, if a site is reachable with more than one name, then just
add symlinks and it should just work.
I found a way to do it using NginX but that's far from minimalistic.
So, I looked around and found that Caddy
was pretty close except it didn't do the automatic stuff.
So, I wrote the missing bit, threw everything in a docker container
and now I have a 30-minute project that serves all my static sites.
It probably needs some tweaking for anyone else specially in the Caddyserver config and maybe in the template it uses to generate sites which is hardcoded.
If anyone actually uses this I can make those things configurable.
I have been using a lot of Crystal for personal
projects for about a year. Think of it like "native Ruby with type inference"
or something like that.
But this post is not about the language itself, it's about one part of its
ecosystem: the shards.
The Nice
Shards are like Ruby gems, or like whatever go calls them nowadays, or
rust crates, just "libraries" that are written mostly in crystal.
The thing is ... they are awesome!
Suppose you want to use markdown in your app. You go to shards.info
which crawls GitHub and finds things written in Crystal. You search for markdown and
you find a few that look good. Suppose you want to use my cr-discount shard.
You just add the shard to your shard.yml and use it, like this:
require "cr-discount"
markdown = "This *is* **markdown**"
html = Discount.compile(markdown)
And that's it, you just integrated it into your build, your code is using it, and
that's all there is to it.
But not only that, suppose you are using a shard like docr
but you find a tiny bug or two. You fork it, fix the bugs and create a PR. If the author is active, they will merge it, and you can go back to using the shard,
but even if they aren't ... you can just use your fork in the meantime.
Just use ralsina/docr instead of marghidanu/docr in your shard.yml and you are
using my fix.
And there's more! Suppose you find some code in your projects that you keep repeating.
For example, I always use the same logging setup in CLI apps:
There is no overhead in your code, you don't have to ask users to install anything,
you just add it to your shard.yml and it's there for everyone that cares.
The Not So Nice
Of course nothing is free of cost.
Because it's easy to create shards, it's easy to abandon shards.
Because it's easy to fork shards, it's easy to atomize the ecosystem.
Because it's easy to find shards and it's decentralized, it's trivial
to poison the supply chain (although TBH it seems to be easy enough
in any language).
So, you have to be careful. You have to check if the shard is maintained, if it's
the best one for the job, if you fork it you need to commit to keeping your fork
working, you always need to push the PR even if the author doesn't pick it up
because it's there for other users.
So, conclusions... they are what they are. For me they are the most practical thing
ever and I often wish Python had something like them, but they are also quite
... scary? And seeing the abandoned shards makes me sad for a language that should
be much more popular than it is.