I have been using Tasks.md for a while
now and ... I like it, but I got the itch to try fixing some things and I didn't
really want to do JS backend code on weekends, so why not try to build a similar
app?
Also I have been wanting to do some "vibe coding" with AI and I seem to have unlimited
Gemini 2.5 in VS Code for some reason, so why not try to do that too?
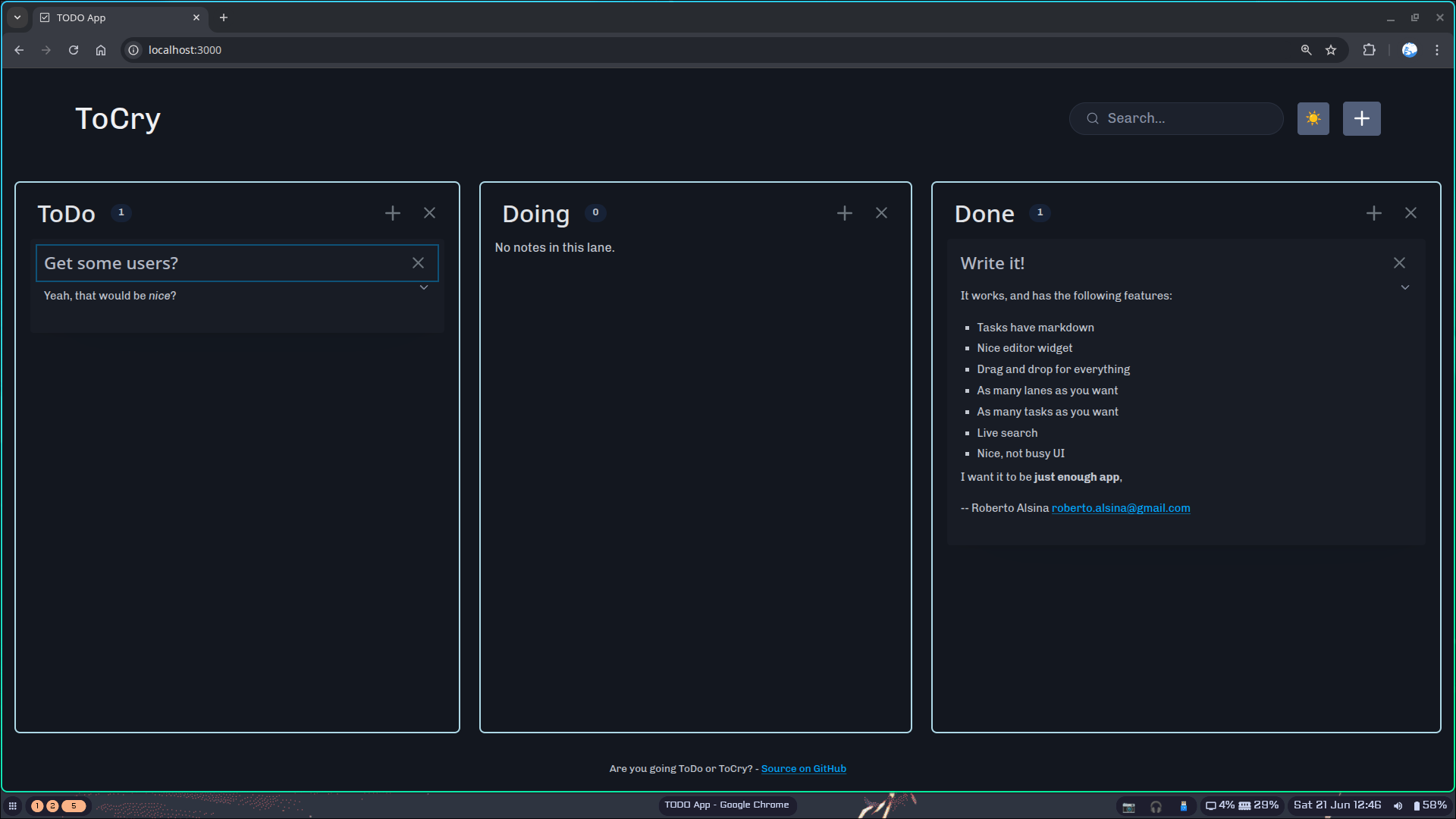
Well: it worked, you can see the result at ToCry, get the app
and use it. It's pretty nice!
Now, I am not saying it's perfect, but it works and I learned a lot. Did AI help?
Well, yeah. Most of the frontend code was AI generated, most of the backend code
is mine with AI autocompleting stuff.
And this got written pretty fast, I only started it two days ago!
In fact, in those two days it was written twice... because the first time
it was absolute garbage.
It was so bad I not only rewrote it, I removed the repo history and pushed the
new code over it. I didn't want to keep that code near, I did not want it to
influence the rewrite.
What Went Wrong The First Time
The first time I went UI-first. I just prompted and prompted and prompted on
a HTML file, trying to get Gemini to generate a nice UI that worked with all
the data kept on the client side.
This seemed to work well, in a few hours I had a nice UI that was
at least functional. However at one point Gemini hit a wall, hard.
Trying to add a new feature or fixing a bug was almost impossible,
Gemini would get in loop after loop, doing and reverting the same
changes over and over.
When I went to manually check the code, it was a bowl of spahetti,
and refactoring it was beyond Gemini's capabilities. Connecting it
to a backend was doable (and got done) but then state was kept
in the client and the backend, and Gemini refused to move it
and consistency was a nightmare.
It became increasingly clear that the code was of no value. So
then I nuked it, salted the earth, and started over.
What Went Right The Second Time
The second time I went backend-first. I wrote a simple backend
in Crystal, with a simple API that returned JSON data for the
entities I wanted to manage: tasks, lanes, boards, etc.
After the data structures were clear, prompts like "create a PUT /note/:id
endpoint that updates the note" worked great. The trick is, of course,
that those requests are pretty much context-free, so Gemini didn't
have to figure out how to connect one thing to another, it was just
writing almost-boilerplate code.
After several of these were created, I intermingled refactoring prompts.
- "Do you see any code that can be moved to a common function?"
- "Please assume this and that are always true and stop checking"
- "Change the names of this and that to something descriptive and short"
I still am not a huge fan of the code Gemini writes. It has a tendency to
do multiple intermediate steps that are not needed and using intermediate
variables in some sort of over descriptive notation all the time.
Ah, and adds stupid comments. Many stupid comments. This is an example
of its code:
self.notes.each_with_index do |note, index| # Changed to each_with_index to get the index
note.save # This saves the note to data/.notes/note_id.md
padded_index = index.to_s.rjust(4, '0')
sanitized_title = note.slug # Note instance method for slug
symlink_filename = "#{padded_index}_#{sanitized_title}.md"
source_note_path = File.join("..", ".notes", "#{note.id}.md") # Relative path for symlink
symlink_target_path = File.join(lane_dir, symlink_filename)
...
Usually, after a function is "finished", I would go and do a pass "for taste"
to make the code more readable, remove the unnecessary comments, and make it
more concise, but the code is functional and this is CRUD, not a fashion
show.
The same happened with the frontend code. I prompted slow, bit by bit:
- Add a button to create a new lane, so when the user clicks it they are asked
for the lane name. Then it calls POST /lane with the right data
- Get the lane data from /lanes and display it as a horizontal list of containers
- Add a button to the lane to delete it, which prompts the user for confirmation
and then calls DELETE /lane/:id
And so on.
Sometimes, I tried larger prompts where I asked for a whole feature, but
those were only occasionally successful. Finding the right granularity is
key, and I found that the best granularity was "one function" or "one component".
Again, mixing refactoring as we went along helped a lot to keep the code
clean and organized, as well as separated in reasonably functions, keeping
spaghetti at bay.
What I Learned
Gemini codes like a junior. It does not understand the big picture, it
does not understand the code it writes, It can write code that works (
I assume because the Internet is full of working code) but it cargo
cults AF.
On the other hand, the code tends to work? And I can fix it pretty quick
when it doesn't? It's not bad at simple refactoring, and what it needs
more than anything is a manager.
Yes, that seems to be the bad news. Coding with AI felt like being a
manager again. A manager with a very, very, very eager junior dev who
doesn't sleep and feels soooo clever by describing uninitialized variables
as "a classic example of a variable that has not been initialized yet".
Would I Do It Again?
Yeah. I have a ton of things I want to write, and this way I can write
them faster. I can also put effort in the parts that matter, like
data structures and algorithms and let Gemini do the silly CSS and CRUD.
Yeah, I don't care if the CSS is redundant, as long as it looks ok
I am happy telling Gemini to "make the rows tighter" and who cares how.
CRUD? It's a solved problem. I will do a pass to clean up.
Data structures? I will do 90% of the work, because that is what
makes the base of the app, and I want it to be solid.
Ethical Thoughts
I feel dirty, and like I am cheating. I am probably stealing code
from other people. Use Gemini to write a Dockerfile and it will
happily autocomplete things with fragments of things including
repo names which exist in the Internet so it's not even a guess,
I know it's copy pasting other people's code.
OTOH, I always copy pasted code from other people's code.